To build and maintain a well-architected cloud solution, you have to consider many aspects that affect the design of your solution. Azure Well-Architected Framework has put together all aspects and grouped them under five main pillars.
This post is a high-level review of the five pillars. If you want to get more details, you can check Azure Well-architected Framework documentation.
In this post, I did my best to:
- Explain the main concepts
- Mention examples of the main azure services that you need to work on like virtual machines, storage, and database.
- Discuss some best practices and tools
If you are a software developer, business analyst, product manager, or anyone who contribute to building a digital product, I think the following overview will be helpful. Because all the team should have a clear understanding of the big picture of the solution architecture.
Let’s start with Azure Well-Architected Framework!
Reliability
It refers to the system’s ability of avoiding failure and functioning well to do what it is supposed to do. In other words, the less time the system is down the more reliable it is.
Another part of reliability is the system’s ability to recover after failure and returns to function properly.
The system is reliable when it’s designed for failure, and if it has a failure, it recovers as quickly as possible, and work properly as expected.
Reliability can be implemented differently based on the requirement. Every system has its own business requirements and SLA commitments with the customers, but not all systems are critical with 99.999% SLA.
Let’s check the availability table that explains what the availability percentage refers to:
Availability Table
| Availability Level | Allowed Downtime Window in One Year |
|---|---|
| 90% | 36.5 days |
| 95% | 18.25 days |
| 99% | 3.65 days |
| 99.5% | 1.83 days |
| 99.9% | 8.76 hours |
| 99.95% | 4.38 hours |
| 99.99% | 52.6 minutes |
| 99.999% | 5.26 minutes |
Example: Reliability with Azure Virtual Machine
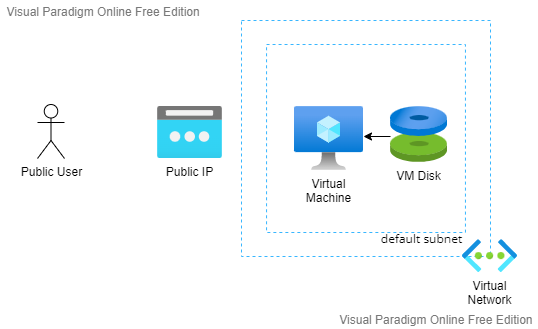
Let’s assume we have a legacy website, and you need to migrate to the cloud. The simplest way to migrate is called lift and shift:
- You will create a virtual machine on the Azure
- Configure the web server software (IIS, Apache) or else in that VM
- deploy your web application artifacts
- Allow public access to the port 80 with a public IP and that’s basically what you need
Let’s skip the database for now and focus on the VM only.
So, the design diagram will look like the following.
Let’s think of reliability:
- What if this machine stopped working, because of disk drive failure?
- What if the server rack of the virtual machine has failed?
- What if the entire datacenter has failed, because of electricity power issue (Yes, I know it’s cloud, but at the end it’s a datacenter 🙂 located somewhere)
- What if the entire region has failed, because of an earthquake.
So, based on the business requirements and the critical level of our application, we will either :
- choose a reliability solution for each failure mentioned above
- or maybe do nothing, because we the business is tolerant to fail at a specific level
The end result is reducing the time of failure.
“Different levels of failure have different options of reliability“
What if the machine stopped working, because of a disk drive failure?
As I mentioned before, The SLA we can provide to our customers depends on the SLA we get from Azure. So, let’s check the SLA of Azure Virtual Machine link here.

To reduce a disk drive failure, we can use Premium SSD storage instead of Standard SSD, or HDD. Premium SSD Ultra Disk will guarantee 99.9% up time for the virtual machine.
| Premium SSD 99.9% | 8.76 hours potential downtime per year |
| Standard SSD 99.5% | 43.92 hours = 1.83 days potential downtime per year |
| Standard HDD 95% | 438 hours = 18.25 days potential downtime per year |
If we chose Premium SSD for the highest availability, we get 8.76 hours as a downtime per year. But, what if the system doesn’t tolerate?
Let’s move to the second level of failure to see if we can reduce the potential downtime even more.
What if the server rack of the virtual machine has failed?
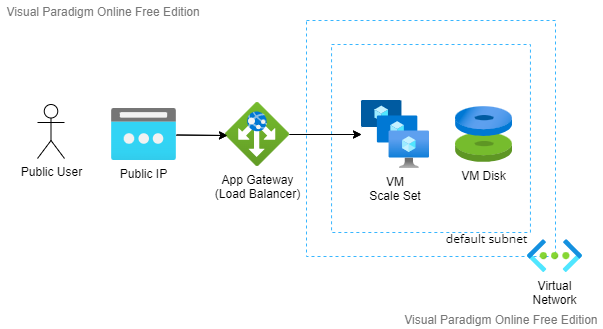
To reduce the server rack issues, we can use two or more virtual machines each hosted in different Fault Domains in the same or different availability set.
Based on the virtual machine SLA, we can get 99.95% of at least one instance of two per year. which means we get 4.38 hours as the potential downtime period per year.

Having two or more virtual machines can be implemented by using Virtual Machine Scale Set instead of creating many copies of the same VM manually.
When having many VM instances, we need a load balancer to balance the load between instances.
Let’s see the diagram after the changes!
What if the entire datacenter has failed, because of electricity power issue?
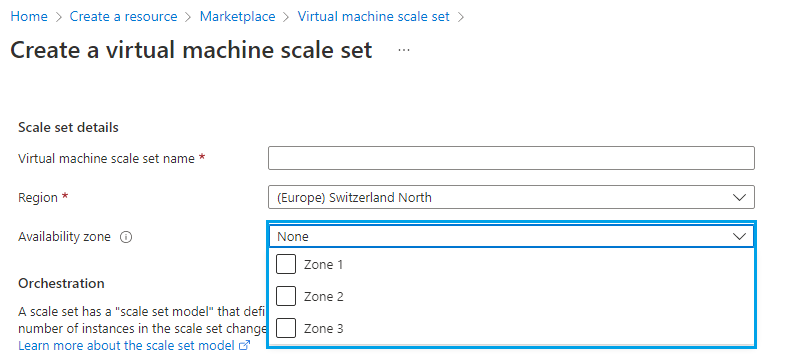
To reduce the datacenter failure, we can use two or more virtual machines each hosted in different availability zones. This will increase the availability to 99.99% which means only 52.6 minutes per year is the potential downtime.
When creating a virtual machine scale set, we can choose many availability zones.
What if the entire region that has failed, because of an earthquake?
To reduce the region failure, we can use two or more virtual machines with different regions.
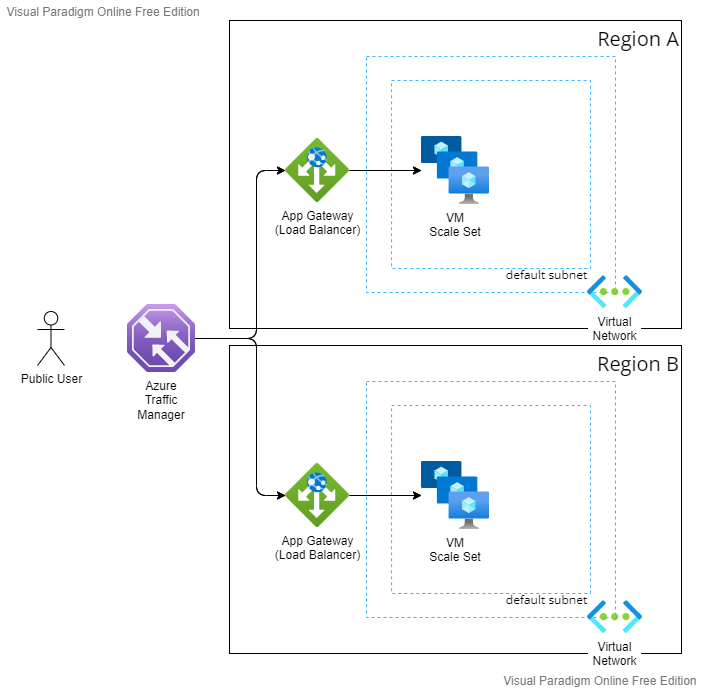
We can’t select the best choice yet, because we have to consider the remaining pillars, especially the cost!
Let’s move to the second pillar, the Security.
Security
Security and Reliability are related. If your service is not secure enough and attackers can cause a security breach, this will reduce the level of reliability your system has.
Security is considered throughout the whole journey of the solution development, the design, the implementation, the deployment, and the operation.
Security covers protecting your data and system from attackers. It also covers the privacy and compliance considerations.
Here are the main areas covered:
- Governance and Compliance
- Identity and Access Management
- Information protection and Storage
- Network Security and Containment
- Security Operations
Security is a huge topic, so I will mention some of the services that Azure provides for each area mentioned above. Then, I will update the design diagram to include some of the services.
Governance and Compliance
Azure Policy provides you with the ability to set the policies for managing your cloud resources and make sure it’s compliant with your domain standards and your organization’s policies.
There are built-in azure policies that can be applied, and you can build your own policies as well. Example of built-in azure policies: Azure Backup should be enabled for Virtual Machines which enforce having azure backup enabled for any virtual machine under a specific resource group.
Identity and Access Management
The architecture will have many infrastructure services. Your team members and users should have a secure way to access the data and the services. Azure AD (Active Directory) provides identity and access management.
Another example of securing the access is Bastion. Azure Bastion is a service that gives you the ability to access virtual machines (RDP/SSH) using the web browser through Azure portal securely. Using Bastion will protect your virtual machines from exposing RDP and SSH ports to the internet.
So, let’s update the diagram and add more workloads to optimize for more security.

Bastion provides the access to all VMs within the provisioned virtual network and peered virtual network as well. That’s why Bastion is in another VN. This is called a hub-spoke network topology.
Information protection and Storage
One of the features is Data Protection at Rest in Azure which means all data is encrypted and guarantee the confidentiality. Data is encrypted by keys managed by Azure by default but, customers can provide their own managed keys as well.
The second workload is Key Vault: Key Vault services support managing and protecting all the secrets and keys used by all your application workloads. Secrets like database connection strings, passwords, certificates will be managed by Key Vault.
Let’s update the diagram and add Key Vault.
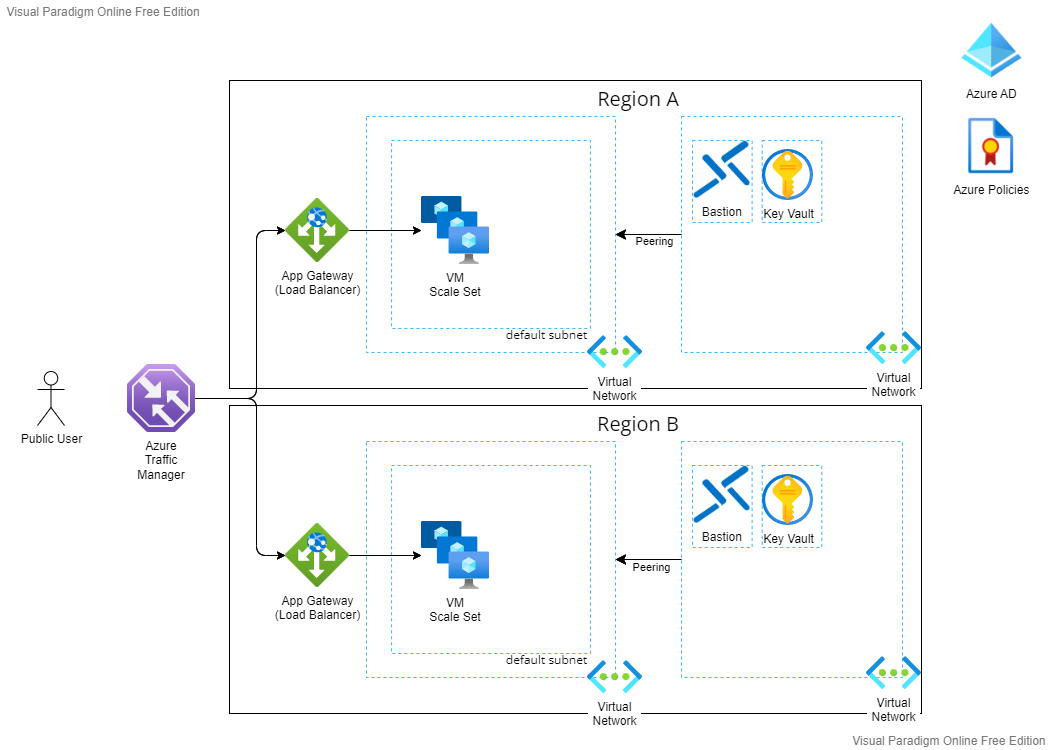
Network Security and Containment
Azure provides many services to secure the network traffic, protect all public endpoints, mitigate attacks, keep your services private in your virtual network, and many others.
Here are some of the services:
- NSG (Network Security Group)
- Application Gateway
- WAF (Web Application Firewall)
- DDOS Protection
Security Operations
Security operations should help detect any security breach or adversary action, then respond quickly, and recover security condition during and after the breach.
It’s Detect, Respond, and Recover.
Azure has many services that will help you reduce the time to detect, respond, and recover from any security breach:
- Azure Advisor
- Microsoft Defender for Cloud Recommendations
- Azure Well-Architected Framework Security Assessment
Let’s move to Cost Optimization.
Cost Optimization
One of the main benefits of cloud services is the ability to decrease the cost, avoid oversized resources and use only the resources you need.
Using Cloud services wisely, controlling the amount of spending, and eliminating cloud waste are all common concerns for any company. Cost optimization can help optimizing the workload usage to get the business value and minimize the spending.
Cost optimization in Azure Well-Architected Framework will be part of different stages of your solution. In each phase, you will follow some principles, use some tools and calculations.
Designing (Design for Cost)
Make sure you have clear business requirements:
- Initial cost
- Performance
- Security and compliance
- Availability
- Region(s) you need to host your workloads in
- The right Azure Subscription(s) you need
- The team capacity and expertise
Check Azure Well-Architected Framework documentation for the extensive list with more details.
After that:
- You can use Azure Pricing Calculator to estimate the cost of workloads you will use. This tool has many cost variables that you can modify to meet your requirements and get a better initial estimation.
- You should also develop a governance strategy to control the cost by using Azure Policy.
- You should define a budget and alerts so you can get notifications when any budget is reached.
Let’s apply that on the last design diagram we have discussed in Security pillar. First, let’s suppose our legacy website budget is:
- The initial monthly budget is $1000 for the legacy website, and it would be great if we can minimize it even more.
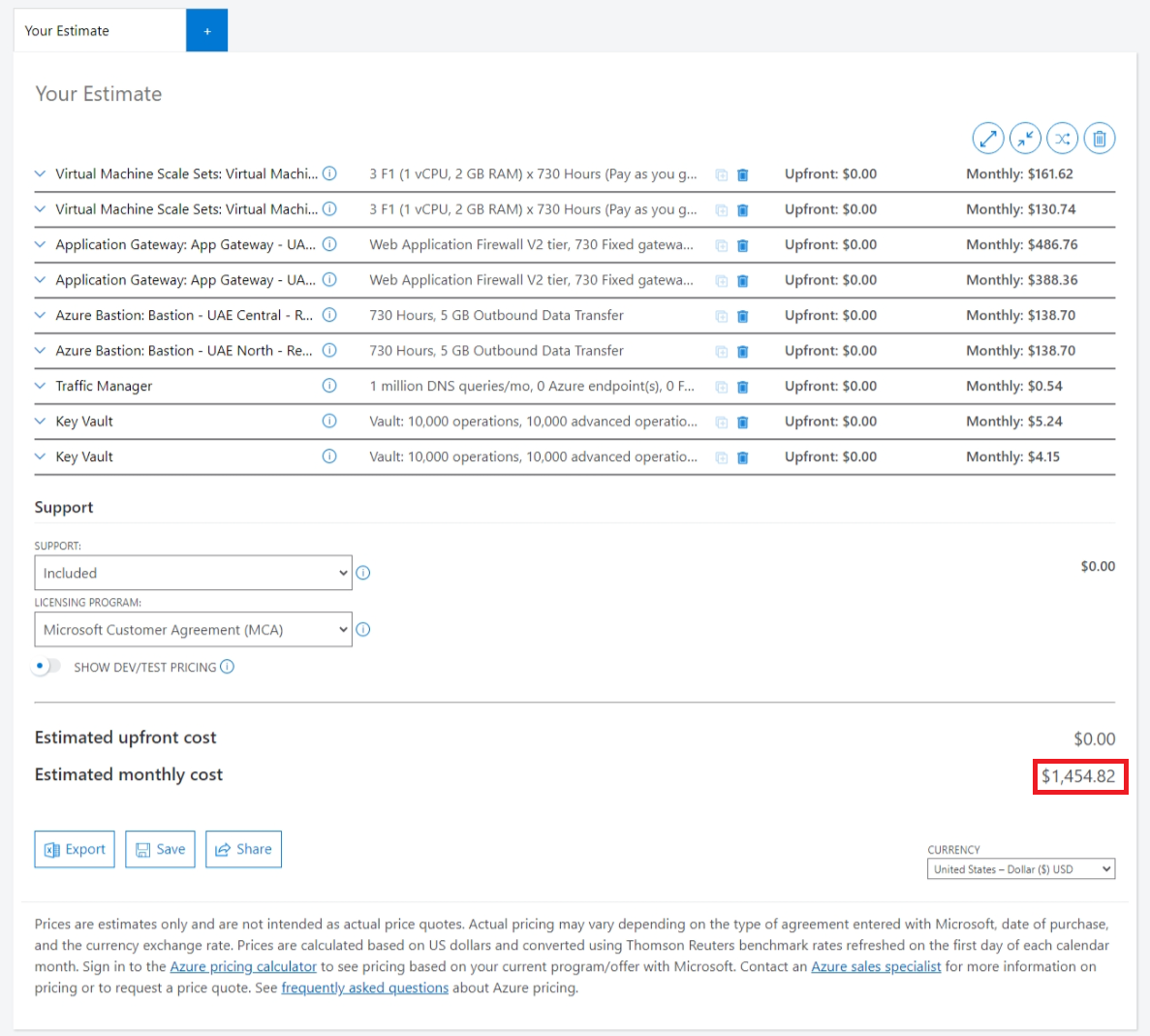
First Estimation
After using the Azure Pricing Calculator, we got the following estimation for our last architecture with two paired regions to support the highest reliability possible.
We also added Bastion, Key Vault as well. This estimation is not complete because we should consider a solution for data replications as well. But anyway, it exceeded the budget, so we have to minimize it.
Second Estimation
After another discussion with the business, we have decided to go with one region only, so I have dropped one region and its workloads.
We also decided to go with UAE North region instead of UAE Central, because UAE Central is more expensive a little bit based on Azure Calculator.
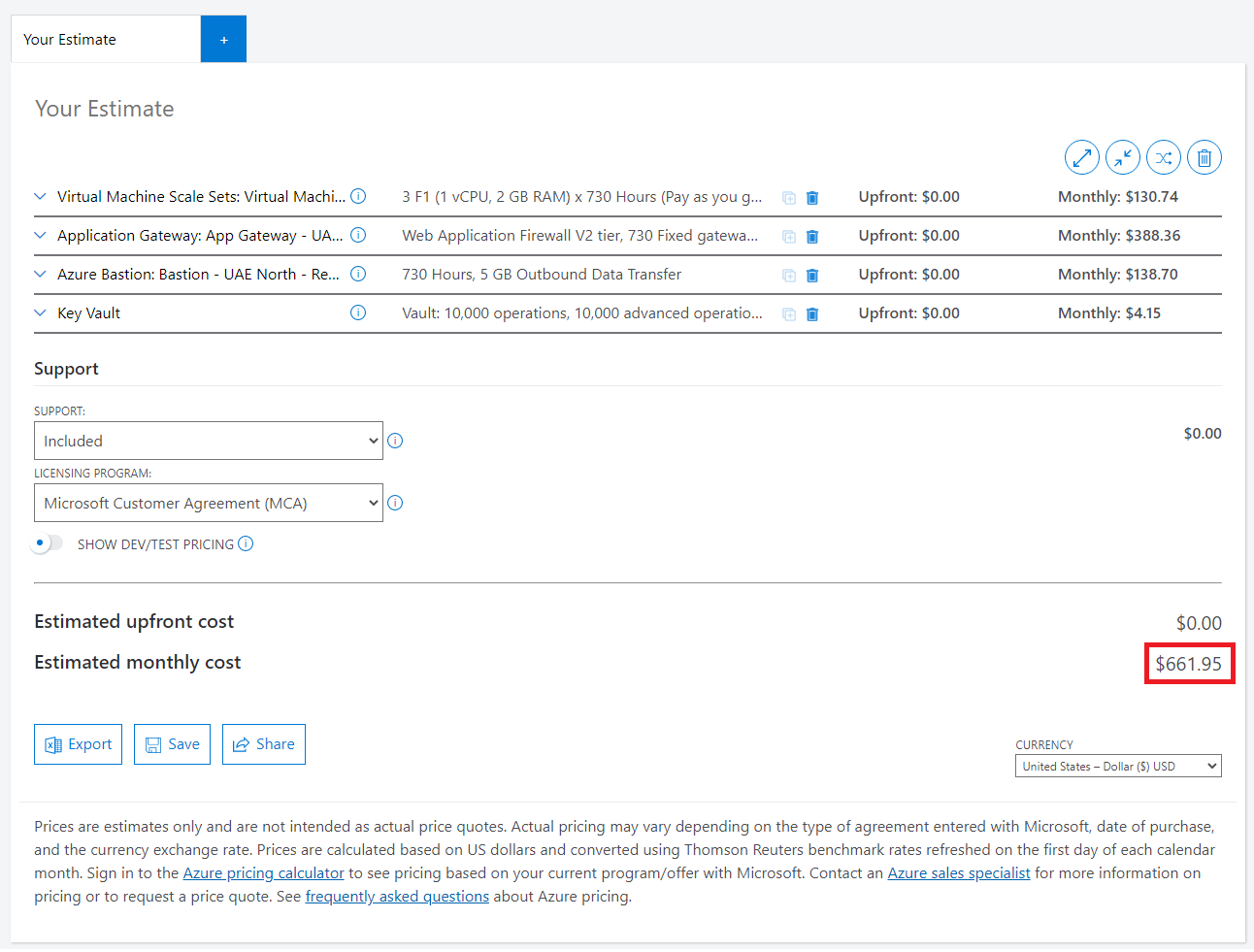
As you notice the estimated cost has dropped to the half almost, and that’s expected because we now need one region instead of two. Kindly note that I didn’t include databases or file storages, but any way, you got the idea of the practice.
We will provision the resources (deploy them) to our Azure Subscription and monitor the consumption.
Monitor
After deploying the resources, we will keep monitoring the budget and the usage. You can use Cost Management on subscription scope or on Resource Group scope.
You can:
- Analyze the cost
- Check what you have spent in a period of time
- Break down the cost by service and location.
- If you already created a budget, you could compare what you already spent to the budget.
- You can also list all the resources and order them by cost.

Optimize
Based on cost monitoring, you can optimize the cost in different way:
- Eliminate cloud waste:
- Shutting down any unused resources
- Scale down any under-utilized resources
- Improve other resources by enabling auto shutdown
- Utilize more in auto scaling.
- Take advantage of Hybrid benefits
- Take advantage of Reservations
- Modernize the architecture and consider using PaaS and Serverless
Operational Excellence
The fourth pillar of Azure Well-Architected Framework is Operational Excellence. No doubt that automation is a key to optimize your operations.
Automation can be done on many levels like:
- Infrastructure deployment, infrastructure configuration using ARM or Bicep templates or Terraform
- Operational tasks using Azure Automation, Azure DevOps for CI/CD pipelines
- Optimize security operations using DevSecOps
DevSecOps
It refers to including all your security practices, processes, tests, as a part of your DevOps process. Instead of having the security checks at the end of the process and just before moving to production, you are including it as part of the DevOps automated process.
This will help expedite the whole process and discover security issues earlier. You will be able to prioritize the issues that need to be resolved earlier and make the right decision.
Security will be included in different stages of the DevOps lifecycle

Release Management
The main purpose of any release management is turning ideas into a working software as quick as possible. This will enhance the time to market and give the ability to experiment the ideas with the customer and get early feedback.
To have a modern release management, the team should invest in continuous deployment, continuous integrations, branching strategies, managing dependencies, and supporting multiple deployment environments.
Monitoring
Monitoring is an essential part of the operation activities. This is where you should have visibility of:
- Software health status and the availability of its different components and services
- Security
- Performance
- Spending
- Tracing and debugging
Azure has many services for monitoring:
- Azure Monitor
- Log Analytics Workspace
- Application Insights
Performance Efficiency
The last pillar of Azure Well-Architected Framework is Performance Efficiency. Performance has become more important than before. In today’s world, slow is the new down.
Design for Performance
Performance and the increase in load should be considered in design, but I don’t think we need to over engineer our design. We could start by monolithic architecture, that’s fine if it satisfies the expected load.
But we should be able to scale out and use more than one instance of our monolithic. So, we should consider building stateless instances and avoiding affinity. This is just a simple example how to design for performance even if you start with a simple architecture.
Another example is using autoscaling feature on azure services. For example, the virtual machines scale set has auto scale feature based on CPU usage.
Auto scale feature allow to configure maximum instance count to avoid unexpected cost.
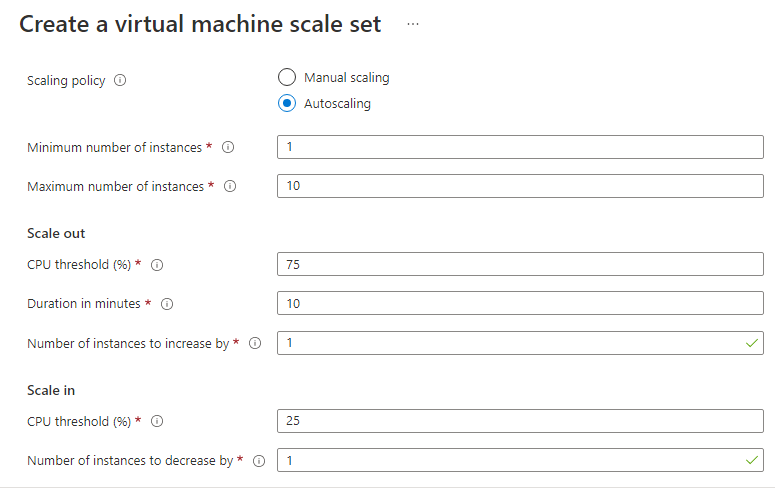
More advanced way to design for performance:
- Consider using Microservices Architecture
- Offloading longtime requests to background jobs.
- Use queues to level the load. you can check this example where I use Azure Functions, Service Bus, and Redis Cache to improve the architecture.
Performance Testing
There are two types for the tests: Load Test and Stress Test.
- Load Test will help knowing the top limit of the load that can be handled by the system.
- Stress Test will help knowing the maximum point of failure where the system will fail.
This is mainly what you need to know to optimize the infrastructure for performance.
Azure Load Testing is fully managed service that can help simulating users’ load to test the application performance. You can either use a simple load test by providing the URL, or create more advanced JMeter test script
Note: when testing performance, it’s not only important to see how the system scale up and out, but also how the system will scale down and in when the test is ended, and traffic has decreased.
Note: The business should communicate any events, concerns and any planned activity that might affect the expected load like a marketing campaign.
Performance Monitoring
To monitor the performance, you need a tool that helps:
- Collecting and aggregating the application logs from different distributed services
- Create correlation of different events and traces from different distributed services so you can understand the flow.
- Provide the metrics and performance counters of different services
The features above and more are provided by Application insights service as a part of Azure Monitor.
Recap of Azure Well-Architected Framework pillars
- Azure Well-Architected Framework has five pillars: Reliability, Security, Cost Optimization, Operations Excellence, and Performance Efficiency.
- The main challenge of designing the right architecture is the trade-off challenge between all pillars.
- Investing more in the team’s capabilities and knowledge is essential!
- Any software developer contributes to the software architecture. when building a modern app on cloud, a software developer should understand the architecture and how the code the developer writes become part of this architecture.
- Amazon Web Services and Google Cloud also has a well-architected framework with the same pillars. The difference between them all is that each provider will explain how to apply the principles using different tools. They also provide their customers with cloud native platforms like Kubernetes. So, studying the pillars will help whether you want to use one cloud provider or multi-clouds.