خدمة Custom Vision هي واحدة من خدمات Azure الإدراكية وهي خدمة تساعد على تحديد الأشياء المختلفة ضمن الصور. بإمكانك اعتبار أن خدمة Custom Vision هي نوع خاص من نماذج الذكاء الصنعي المتعلقة بتصنيف محتوى الصور.
لكن بدلاً من توصيف الصورة ككل فإنه يحدد الأشياء ضمن الصورة ويضع توصيف لمحتوى الصورة.
في هذه التدوينة ستتعلم كيف يمكن أن:
- تنشئ خدمة Custom Vision
- تقوم بتدريب نموذج تعلم الآلة الخاص بالخدمة
- اختبار نموذج تعلم الآلة
- نشر خدمة API يمكن استخدامها ضمن النظام الذي تقوم ببنائه
هذه التدوينة هي جزء من تدوينة مفصلة عن سيناريو سحابي متعلق بتصميم برمجية سحابية عن حملة تسويقية تقوم بطرح مسابقة تحتاج إلى عمليات تحقق من الصور باستخدام الذكاء الصنعي.
إنشاء خدمة Custom Vision
سأذكر خطوات إنشاء خدمة Custom Vision خطوة بخطوة عن طريق Azure Portal. الخطوة الأولى تبدأ بالبحث عن الخدمة في متجر Azure “Azure Marketplace”
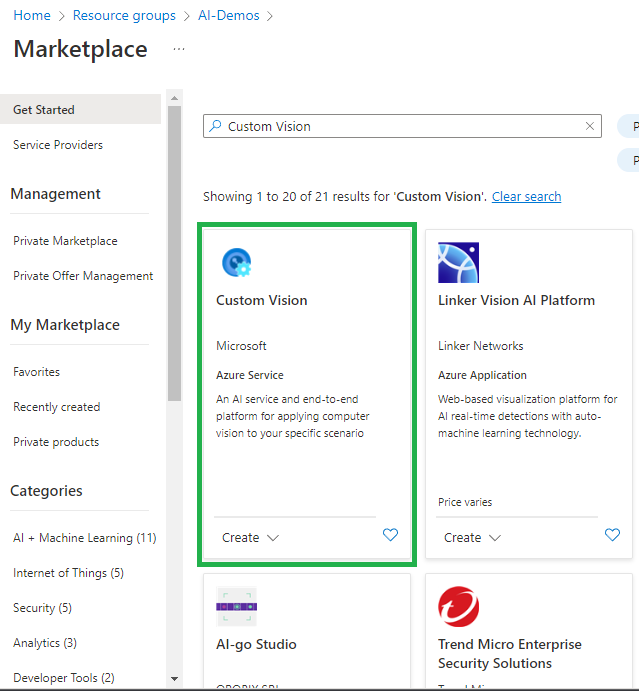
نضغط على “Create” وننتقل إلى أول صفحة لإنشاء خدمة Custom Vision
- اختر المنطقة الجغرافية بحسب المتطلبات “business requirements”
- أدخل اسم الخدمة
- اختر آلية التسعير: يمكن استخدام الشريحة المجانية ولكن في حالة الproduction يجب اختيار الشريحة Standard من أجل من خدمة تدريب النموذج وخدمة التوقع (training and prediction)
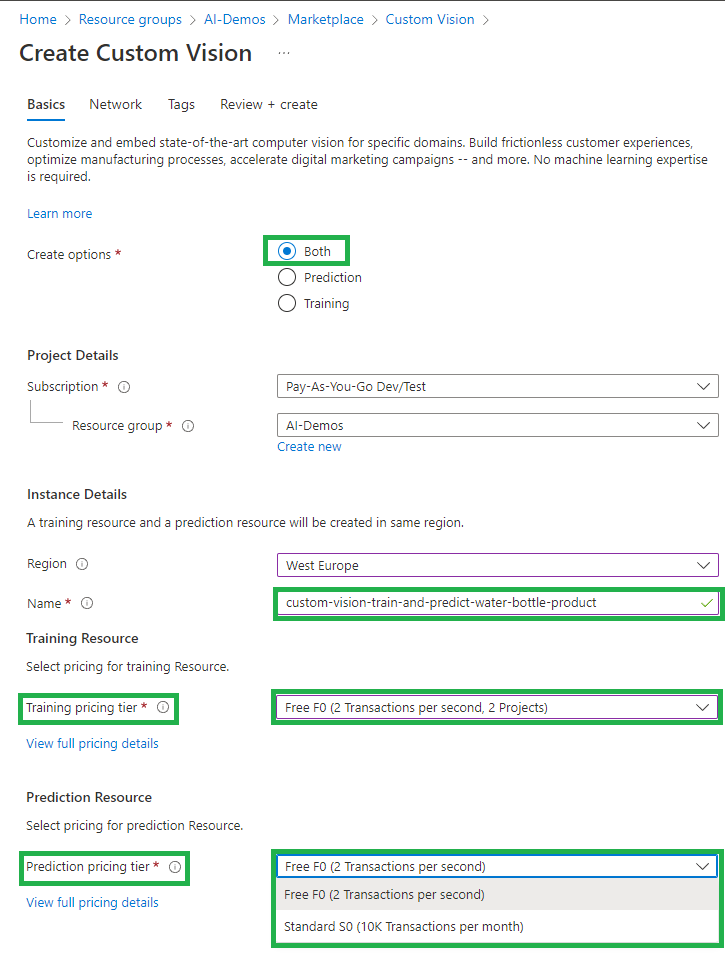
بعد ذلك، اضغط التالي وانتقل إلى تبويبة إعدادات الشبكة “Network”:
- في حالة الاختبار والتدرب بإمكانك اختيار الخيار الأول وهو إمكانية وصول الخدمة من كل الشبكات حيث تكون الخدمة قابلة للوصول عن طريق الانترنت public internet
- في السيناريوهات الحقيقية يجب منع الوصول للخدمة من كل الشبكات واستخدامة نقطة وصول خاصة Private endpoint
بعد الانتهاء من عملية التحقق من المدخلات يمكنك الضغط على “Create” و انتظر حتى يتم إنشاء الخدمة.
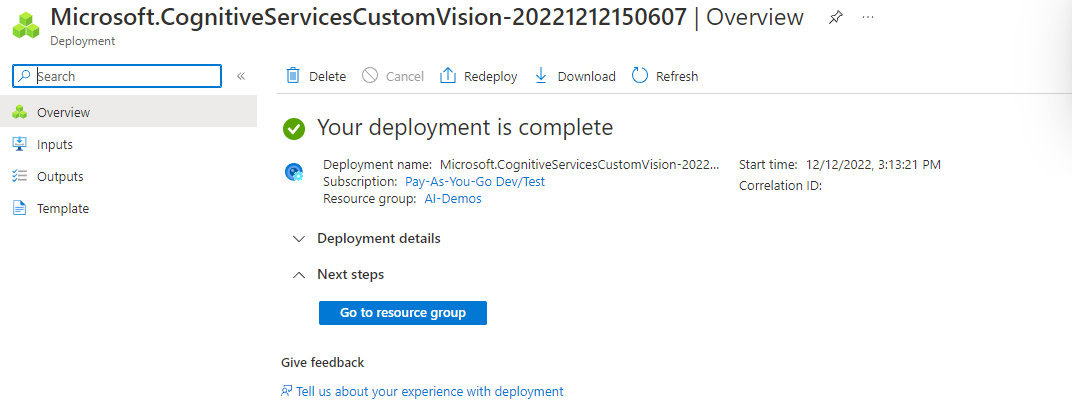
والآن عندما تذهب إلى مجموعة الموارد Resource Group ستجد موردين قد تم إنشاؤها :
- خدمة التدريب لنموذج تعلم الآلة المخصص Training Service
- خدمة التوقع التي ستستخدم لاستدعاء النموذج المدرب والجاهز للاستخدام Prediction service
والآن أصبحت الخدمة الجاهزة ويجب أن تنتقل للخطوة القادمة وهي:
إنشاء مشروع Custom Vision
في البداية انتقل الى موقع https://customvision.ai ثم قم بتسجيل الدخول باستخدام نفس معلومات الدخول الخاص بحسابك على الخدمة السحابية Azure والتي تسخدمها للوصول عن طريق Azure Portal.
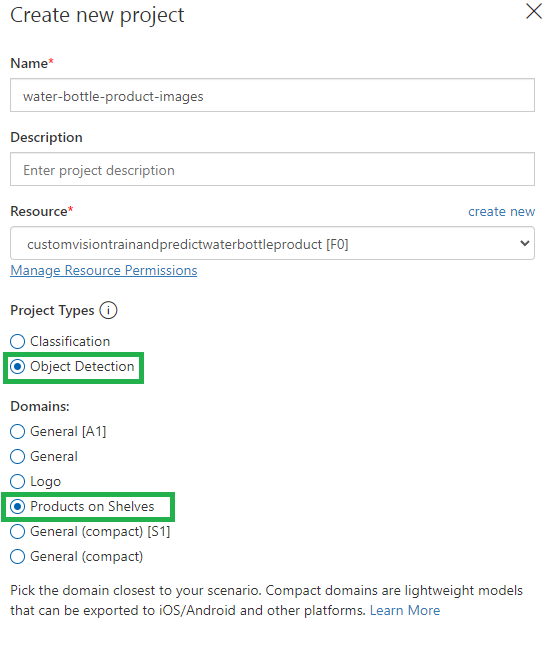
ثم قم بإنشاء مشروع جديد
- أدخل اسم المشروع وتوصيف نصي مختصر
- ستلاحظ أن الخدمة التي أنشأتها بالخطوة السابقة ستظهر بالقائمة المنسدلة ، عليك اختيارها
- اختر نوع المشروع والذي سيكون بهذه الحالة Object Detection
- اختر أقرب مجال مشابه للحالة التي تريد أن تقوم بتدريب النموذج عليها، سأختار المجال “منتجات على الرفوف” “Products on Shelves”
بعد ذلك سيتم توجيهك إلى صفحة المشروع والتبويبة الأولى هي “صور التدريب”، هنا ستقوم بتحميل الصور التي ستستخدم لتدريب واختبار النموذج.
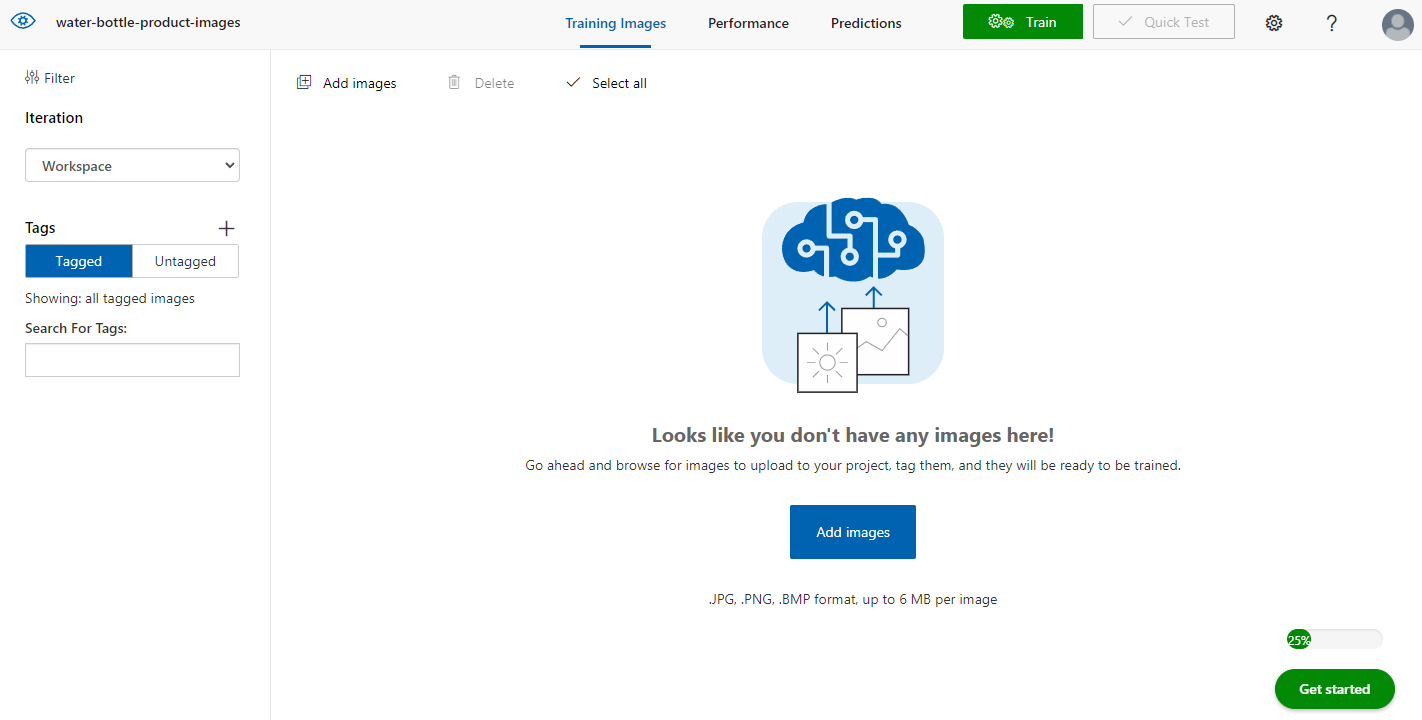
قبل الانتقال للمرحلة القادمة، تستطيع الاطلاع على اعدادات المشروع من خلال الواجهة التالية و فيها تستطيع أن تتطلع على حالة الاستخدام المتاحة لك بحسب شريحة السعر التي اخترتها عندما أنشأت الخدمة في الخطوة الأولى.
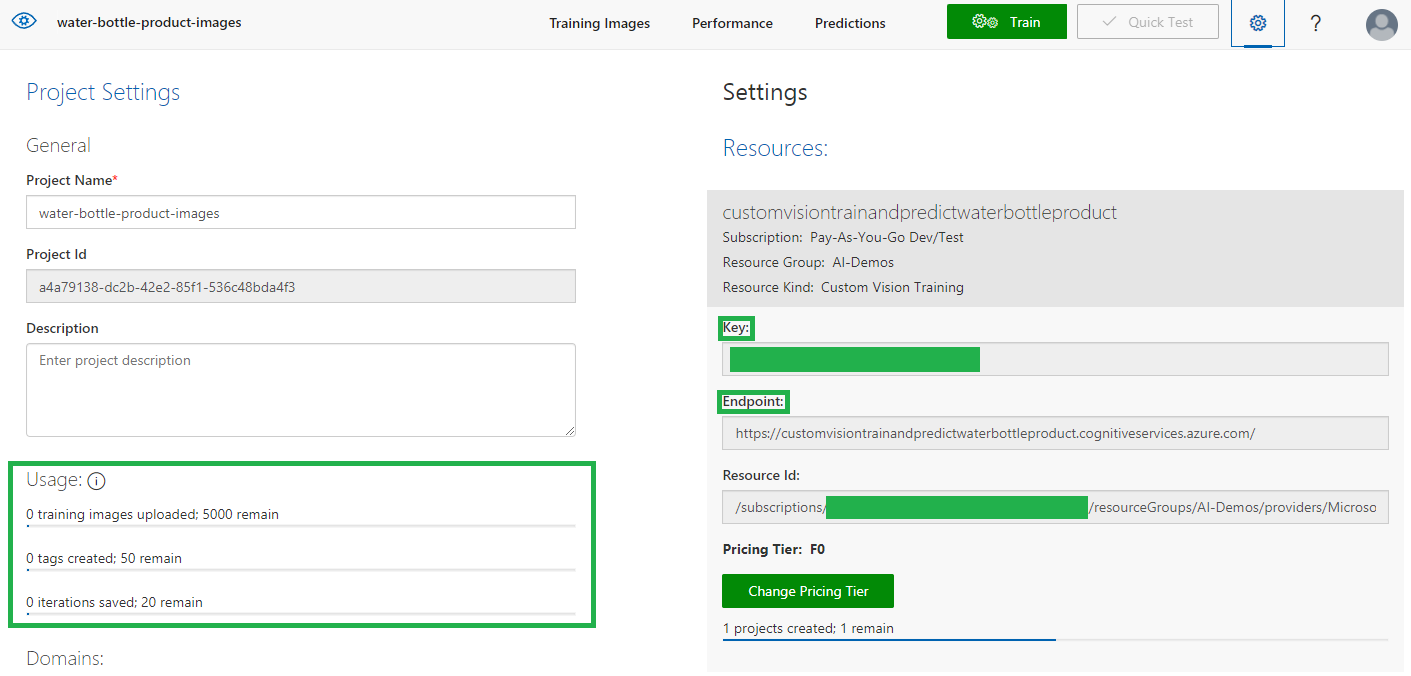
تدريب ثم اختبار نموذج تعلم الآلة (Object Detection Model)
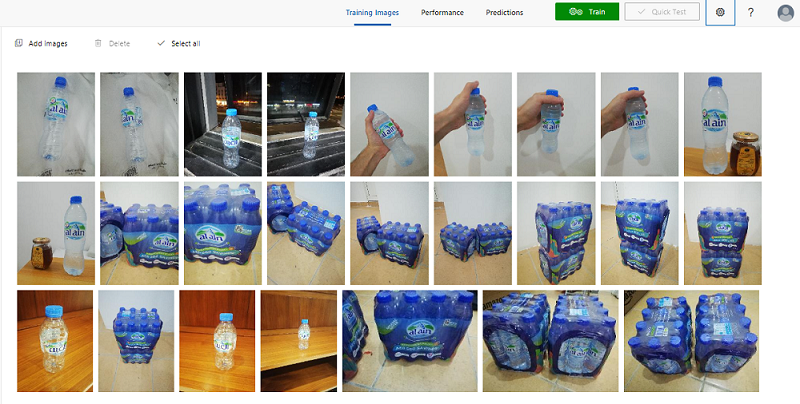
لتتمكن من تدريب النموذج، يجب أن تقوم بتحميل الصور التي تحوي الأشياء التي تريد من النموذج أن يتعرف عليها، وبعد التحميل ستقوم بوضع التصنيف على كل منطقة بالصورة.
قمت في هذا المثال بتحميل 34 صورة تحوي المنتج الذي أريد أن أدرب النموذج عليها، بالطبع بذلت جهدي بالتقاط صورة متنوعة بحالات مختلفة لمحاكاة الصور الحقيقية التي سيتم أخذها من المستخدم النهائي.
يجب أن تحمل 15 صورة على الأقل من اجل كل تصنيف أو شيء تريد أن تدرب النموذج عليه، فمثلاً بهذه الحالة أريد من النموذج أن يتعرف على قنينة المياه أو علبة العبوات وكذلك اللوغو الخاص بالشركة. ومن الأفضل رفع العدد من 15 إلى 50 صورة من أجل كل تصنيف للحصول على أداء أعلى.
هذه هي طريقة تحديد “Tagging” التصنيفات ضمن كل صورة:


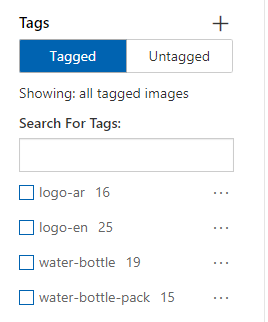
قمت بتحديد التصنيفات Tags التالية في الصور الخاصة بالتدريب:
- “logo-ar” من أجل اللوغو باللغة العربية
- “logo-en” من أجل اللوغو باللغة الإنكليزية
- “water-bottle” من أجل عبوه المياه الواحدة “القنينة”
- “water-bottle-pack” من أجل علبة عبوات المياه
بعد الانتهاء من عملية التصنيف “Tagging” يمكنك معرفة مجموع التصنيفات في كل الصور، تذكر يجب أن يكون هناك 15 تحديد لكل تصنيف “tag” على الأقل.
الخطوة التالية هي القيام بتدريب النموذج:
- اضغط على “Train Model” ثم اختر التدريب السريع “Quick Training”، بإمكانك اختيار الخيار المتقدم “Advanced” ولكن للتجربة السريعة سنقوم بالاختيار الأول.
- اضغط على “Train” في النافذة المنبثقة
- سيلزم التدريب السريع بضع دقائق بحسب كمية الصور التي تم تحميلها، في حالتي السابقة تتطلب الأمر من 5 إلى 7 دقائق فقط في كل مرة أقوم بتدريب النموذج.

في كل مرة نقوم بتدريب النموذج يجب أن ننتبه إلى 3 مؤشرات أداء:
- Precision: يدل هذا المؤشر على عدد مرات التوقع الناجحة التي قام بها النموذج بالنسبة لمجمل عدد مرات المحاولات الكلي. لنفرض لدينا 100 صورة قام النموذج بتوقع الأشياء فيها، ويجد فقط 70 صورة تحوي عبوة مياه فقط من أصل المئة صورة ، عندها سنقول أن دقة النموذج 70%.
- Recall: في حال كان لدينا 100 صورة تحوي فعلاً عبوة مياه، ولكن النموذج استطاع تحديد 80 صورة فقط ، عندها نقول أن معيار التذكر هو 80%.
- mAP (mean average precision)
بإمكانك التحقق من قيم المؤشرات سواء عللى مستوى النموذج ككل، أو من أجل أداء النموذج في توقع كل صنف (Tag) بشكل منفصل.
النتائج التالية من أجل 3 تجارب تدريب منفصلة للنموذج وفي كل تجربة قمت باختيار مجال تدريب مختلف (different domains).
الدورة الأولى باستخدام مجال (product on shelves)
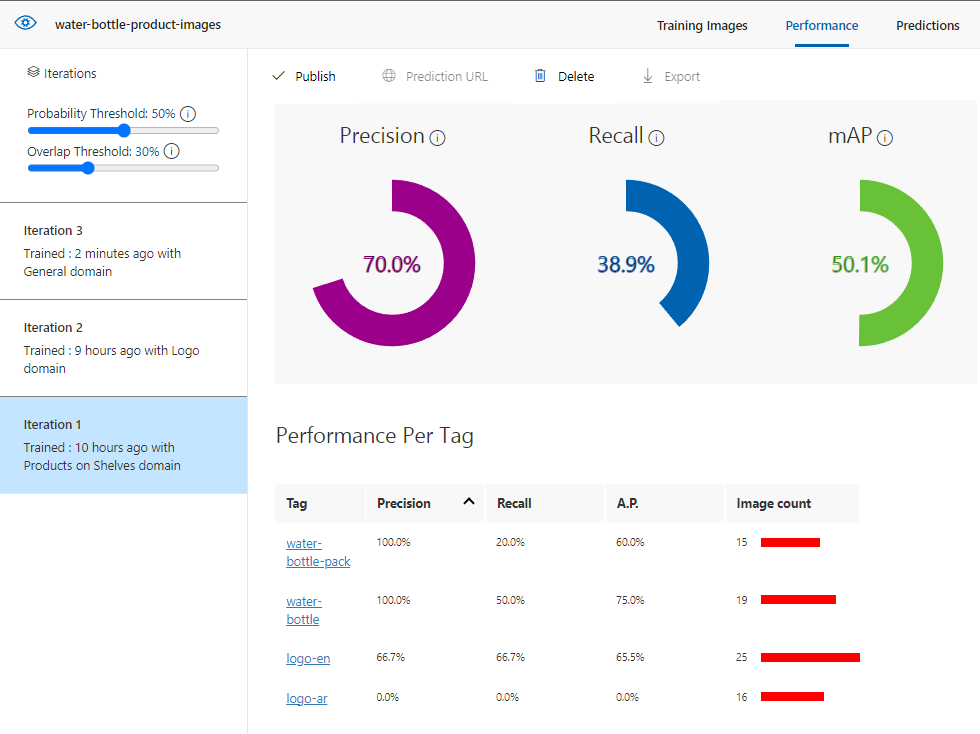
قمت باختبار النموذج بعد الدورة الأولى والنتائج لم تكن مرضية بشكل كافٍ:
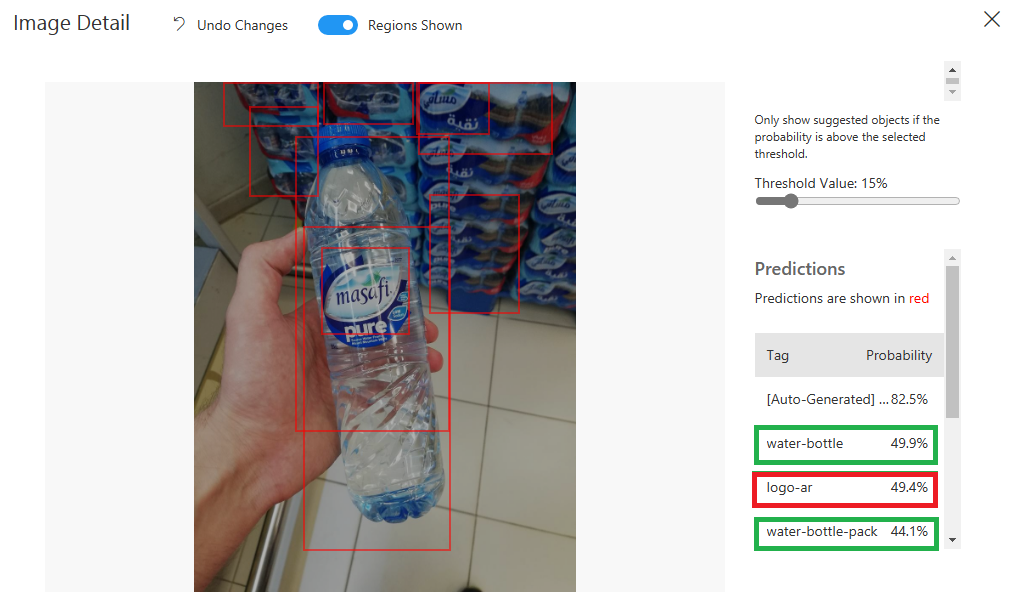
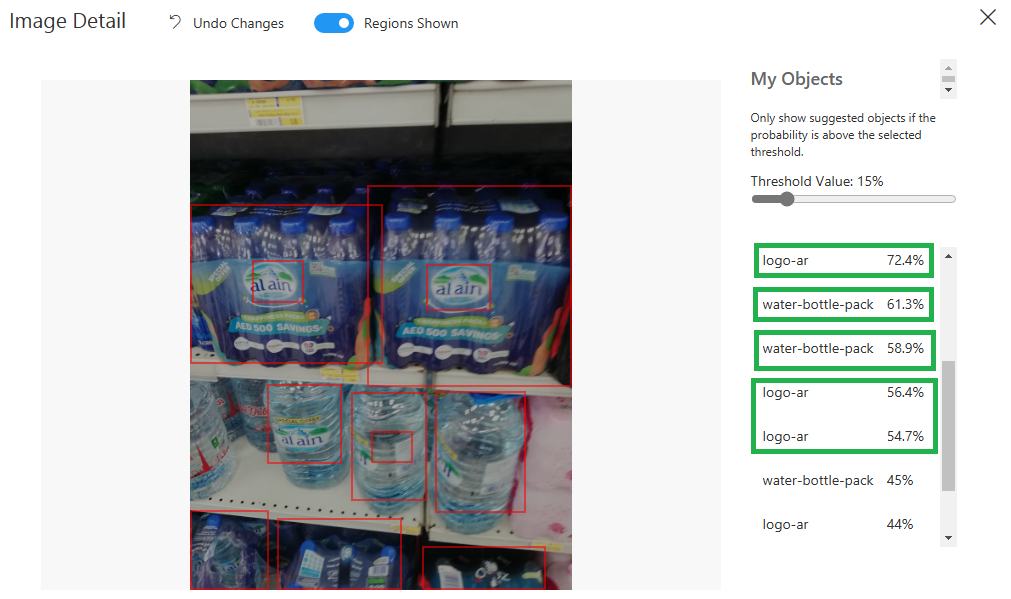
في الحقيقة قمت باختبار الموديل بعدة صور ولكن أعتقد من الجديد تجربة تدريب النموذج ولكن ضمن مجال آخر
لنجرب مجال اللوغوهات !
الدورة الثانية باستخدام مجال (Logo)
أيضاً النتيجة ليست مرضية، وبعض التوقعات كانت خاطئة جداً، هذا يؤكد أهمية اختيار المجال الأقرب للحالة التي نحتاجها.
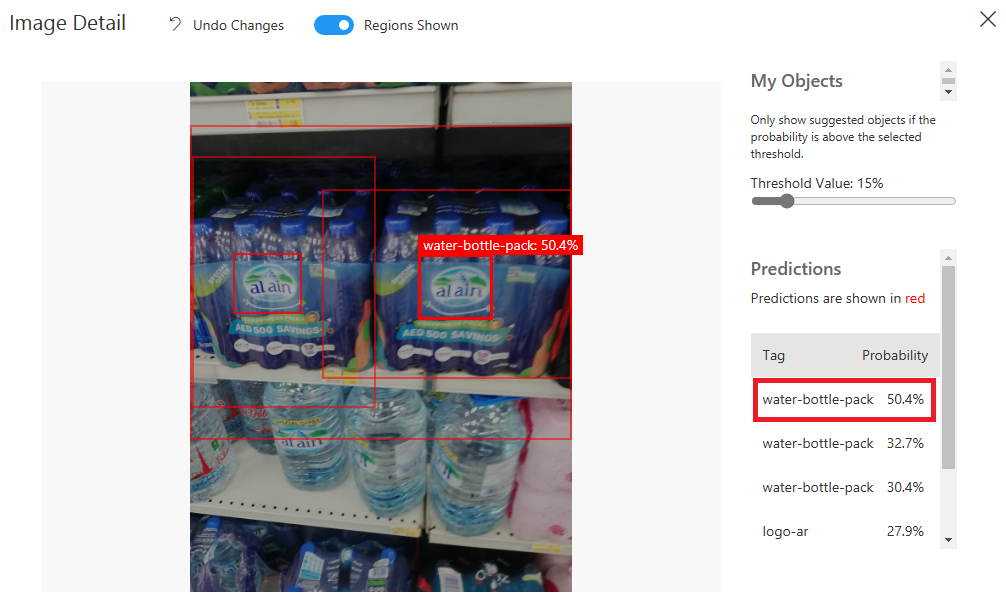
لنجرب مجال ثالث!
الدورة الثالثة باستخدام مجال (General)
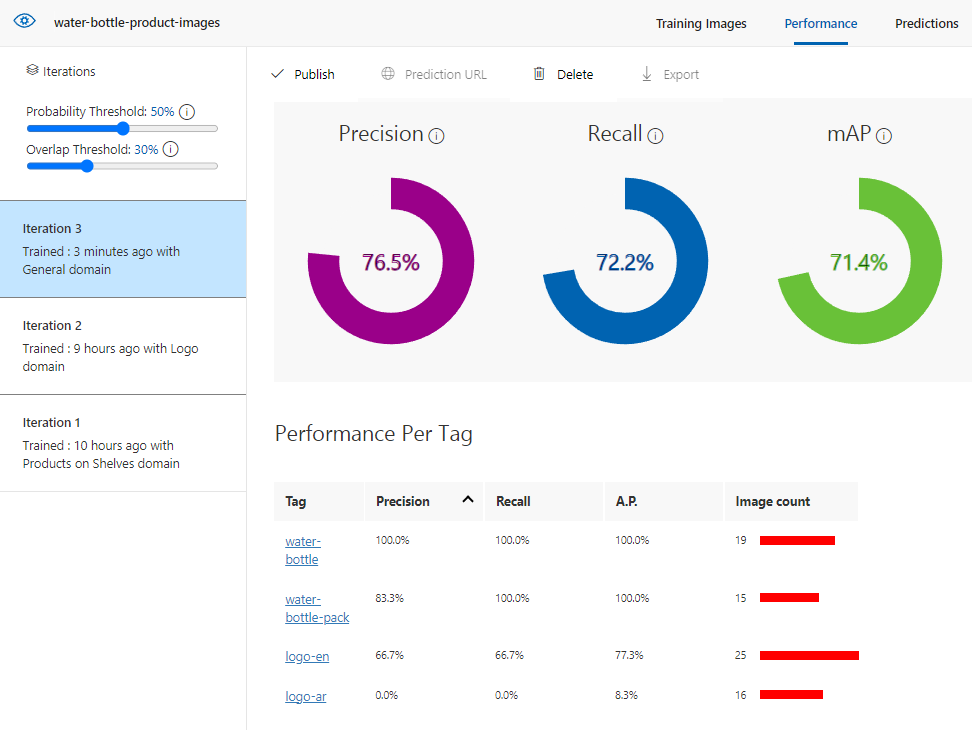
معايير الأداء الثلاثة كانت مقبولة تقريباً
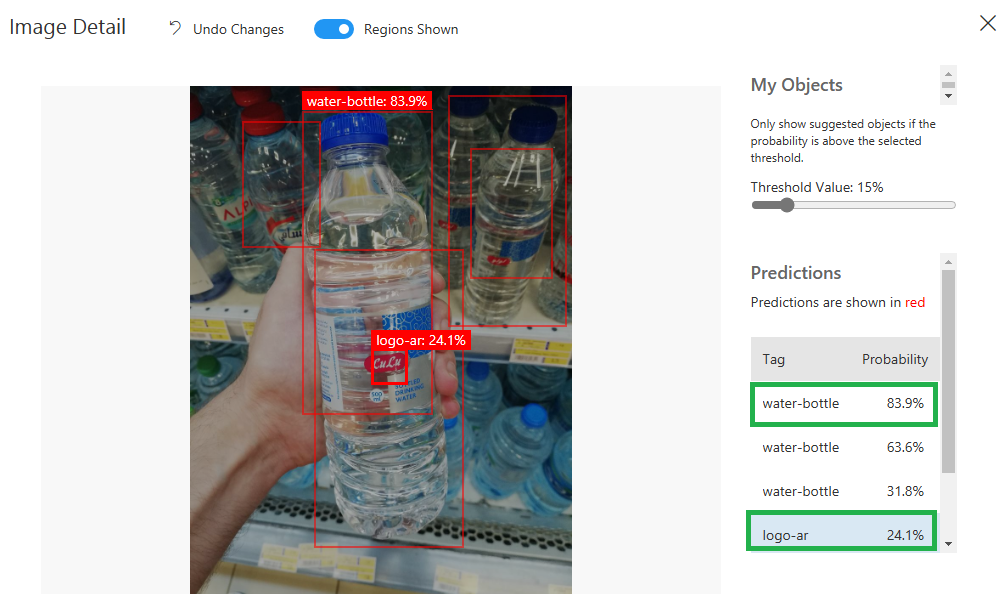
كما هو واضح، أن الدورة الثالثة كانت أفضل من سابقاتها، ولكن يوجد إمكانية لتحسين الأداء أكثر، وخاصة التصنيف “logo-ar” و “logo-en”، وذلك عن طريق مايلي:
- إضافة صورة أخرى بخلفيات متنوعة، درجات إضاءة مختلفة، ومن زوايا متعددة
- سأعمل على دمج التصنيفين الخاصين باللوغو وجعلهم تصنيف واحد، فعلى الرغم من كونهما لغتان مختلفتان ولكن كرسم يوجد تشابه كبير يصعب على النموذج تحديدهم.
الدورة الرابعة باستخدام المجال (General) مجدداً ولكن بعد إجراءات التحسين
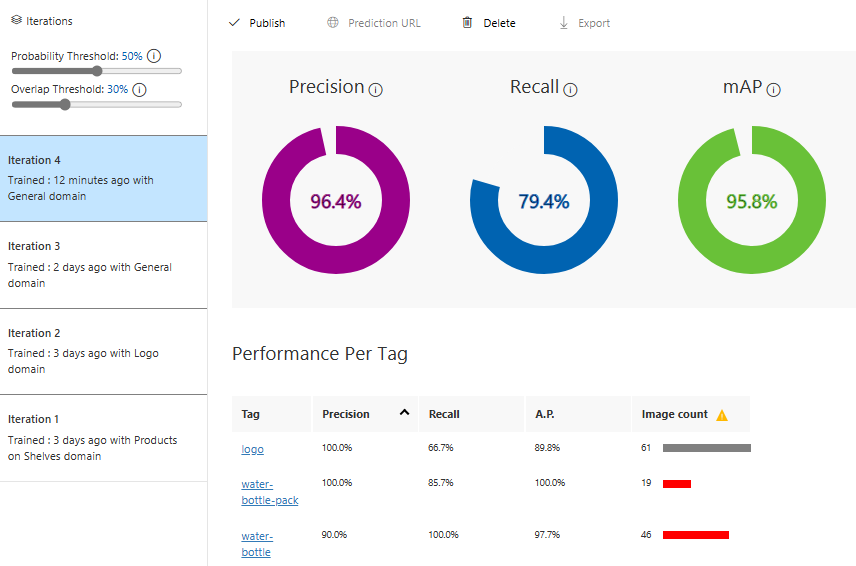
معايير الأداء الآن أصبحت أفضل بشكل واضح، لنجرب صورة ما:
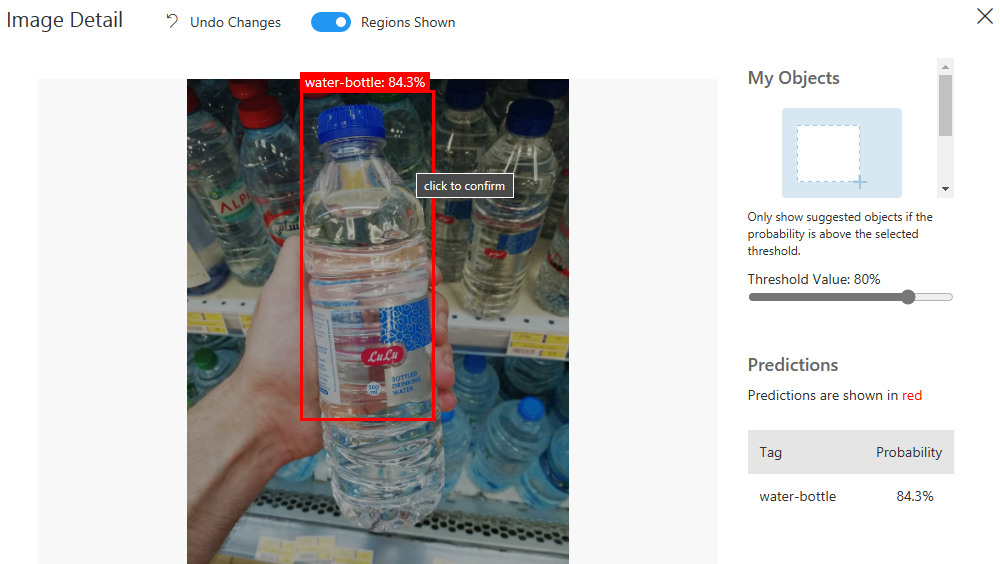
نشر النموذج الذي تم تدريبه
بعد الانتهاء من التدريب والوصول إلى نتائج مقبولة، نستطيع نشر النموذج لكي يتم استخدامه كجزء من البنية البرمجية أو الحل البرمجي (Solution) الذي نسعى لتطويره:
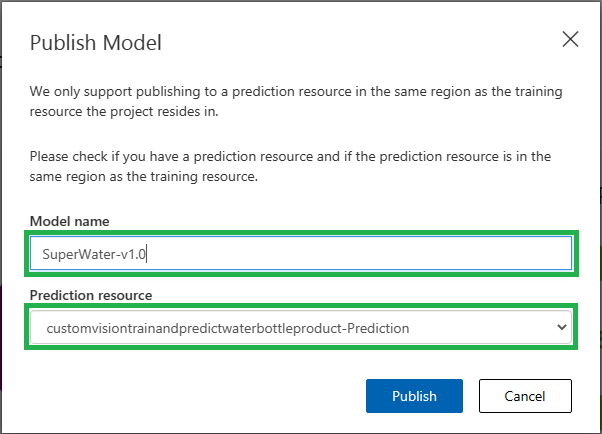
- نضغط على الدورة الرابعة التي نريد نشرها ثم نضغط على “Publish”
- يجب وضع اسم للنموذج
- يجب اختيار الخدمة السحابية التي تم إنشائها في أول خطوة بالمقالة والتي تنتهمي باللاحقة -Prediction
بعد أن تم نشر النموذج بشكل ناجح، نستطيع الآن استخدامه كخدمة برمجية API، حيث يمكن الضغط على “Prediction URL” لمعرفة كيف يمكن استدعاء الخدمة عن طريق كتابة كود.
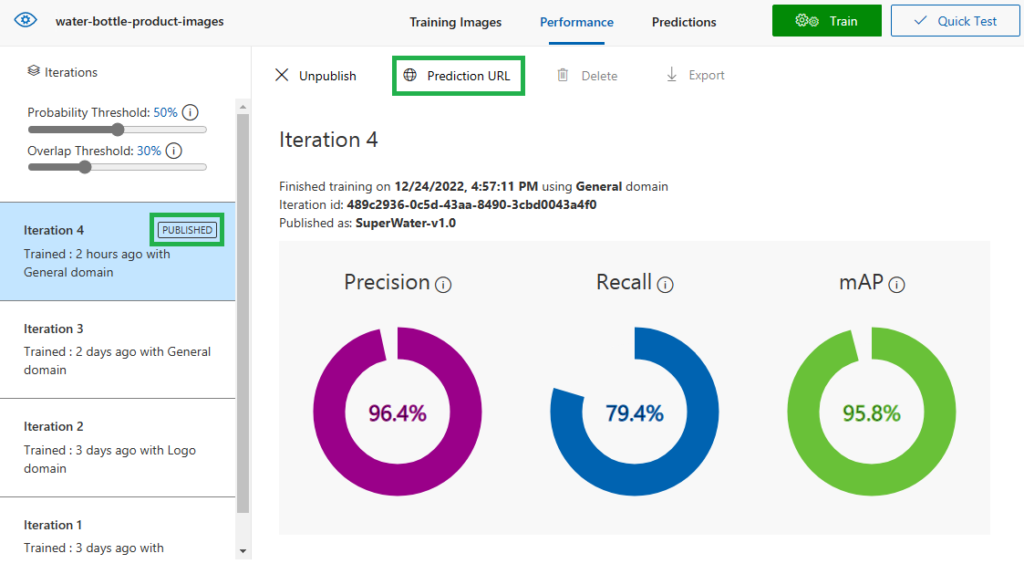
تم نشر النموذج كخدمة ويمكن استخدامه ضمن الحل البرمجي Cloud Solution
ولكن يوجد طريقة أخرى لاستخدام النموذج الذي تم تدريبه، حيث يمكن تصدير النموذج ليتم استخدامه كجزء من تطبيق الجوال iOS/Android أو دمجه كجزء من صفحة ويب واستخدامه بشكل مباشر ضمن مشتعرض الانترنت.
ولكن قبل ذلك يجب تدريب النموذج على مجال يمكن تصديره،
الدورة الخامسة لتصدير النموذج حتى يستخدم مع TensorFlow.js
Custom Vision Service تدعم عدة طرق للتصدير:
- TensorFlow for Android
- Tensorflow for JavaScript Frameworks like React, Angular, and Vue
- CoreMl for iOS11
يوجد خيارات أخرى مذكورة في التوثيق هنا.
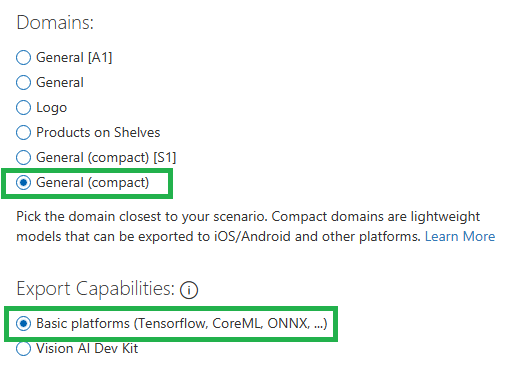
قبل التصدير يجب أن نستخدم مجال مختلف وهو General (compact). ويجب أن نقوم بإعادة تدريب النموذج مرة ثانية بعد تغيير المجال.
يمكن تغيير المجال من أعدادات المشروع :
ثم ننتقل إلى تبويبة الأداء مرة ثانية ونضغط “Train” مرة ثانية.
بعد انتهاء التدريب يمكن ضغط “Export” إلى مكتبة TensorFlow.js
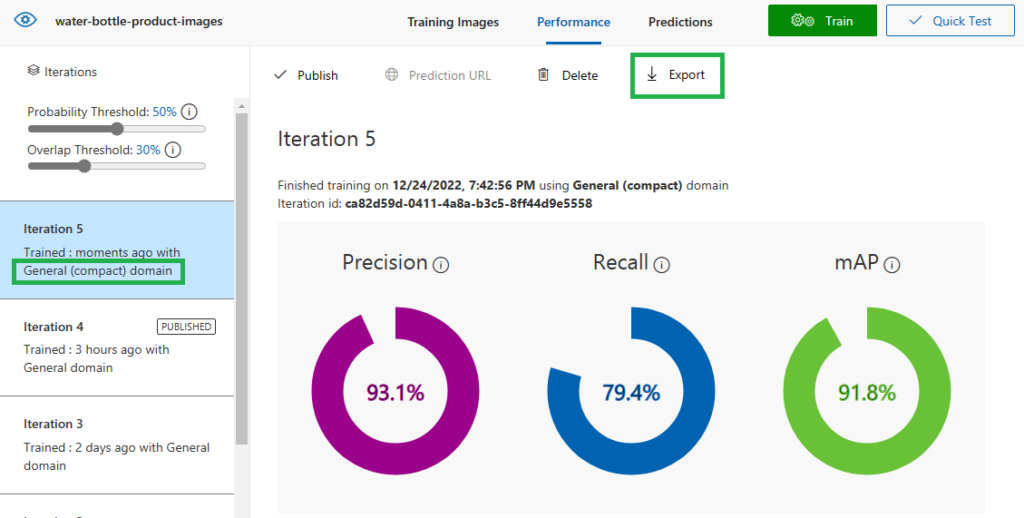
قم باختيار “TensorFlow”, ثم قم بتنزيل الملف على هيئة zip.

الملف الذي سيتم تنزيله يحوي عدة ملفات بعد فك ضغطه: يمكن استخدام الباكج التالية npm package لمعرفة كيفية دمج نموذج الخدمة في صفحة الويب.
قمت بوضع مثال بسيط على حسابي في GitHub GitHub repo.
الصورة التالية تظهر مثال كيف يمكن استخدام النموذج ضمن صفحة الويب.

الخلاصة
- يمكنك استخدام خدمة Custom Vision لتدريب واختبار ثم نشر نموذج تعلم الآلة الخاص بك لكي يتوقع وجود أشياء من أصناف معينة ضمن الصور.
- يمكن أيضاً تصدير النموذج ليتم استخدامه كجزء من تطبيق الجوال iOS/Android أو يمكن تضمينه ضمن صفحة الويب.